Introducing Misal 7B & 1B
Empowering Marathi GenAI
Empowering Marathi GenAI

The ever evolving landscapes of large language models and their applications, has seen multiple efforts in the recent past for improving multilingual abilities of these models. Here we take a small step to contribute to this effort by introducing Misal 7B and 1B, a pretrained and instruction tuned large language model based on Meta’s Llama 7B, and TinyLlama architecture respectively for Marathi.
"Misal" was developed to address the limitations of the Llama2 model, which was predominantly trained on English data, with only a small percentage dedicated to other languages, including code and miscellaneous languages. With mere 2% of its data representing non-English languages, it's evident that Llama2 is not optimally fine-tuned for building GenAI applications in languages beyond English. To fill this gap and support the multilingual development of GenAI for Indian languages, a Marathi Large language model named "Misal" was created.
Today, we're releasing total of 4 Misal models:
- Marathi Pre-trained LLM - Misal-7B-base-v0.1 & Misal-1B-base-v0.1
- Marathi Instruction tuned LLM - Misal-7B-instruct-v0.1 & Misal-1B-instruct-v0.1
Next, we'll dive into the three-step procedure used to make Instruction Tuned Misal models. Training procedure followed is very similar for both 7B and 1B model. Below we discuss procedure for building Misal-7B model.
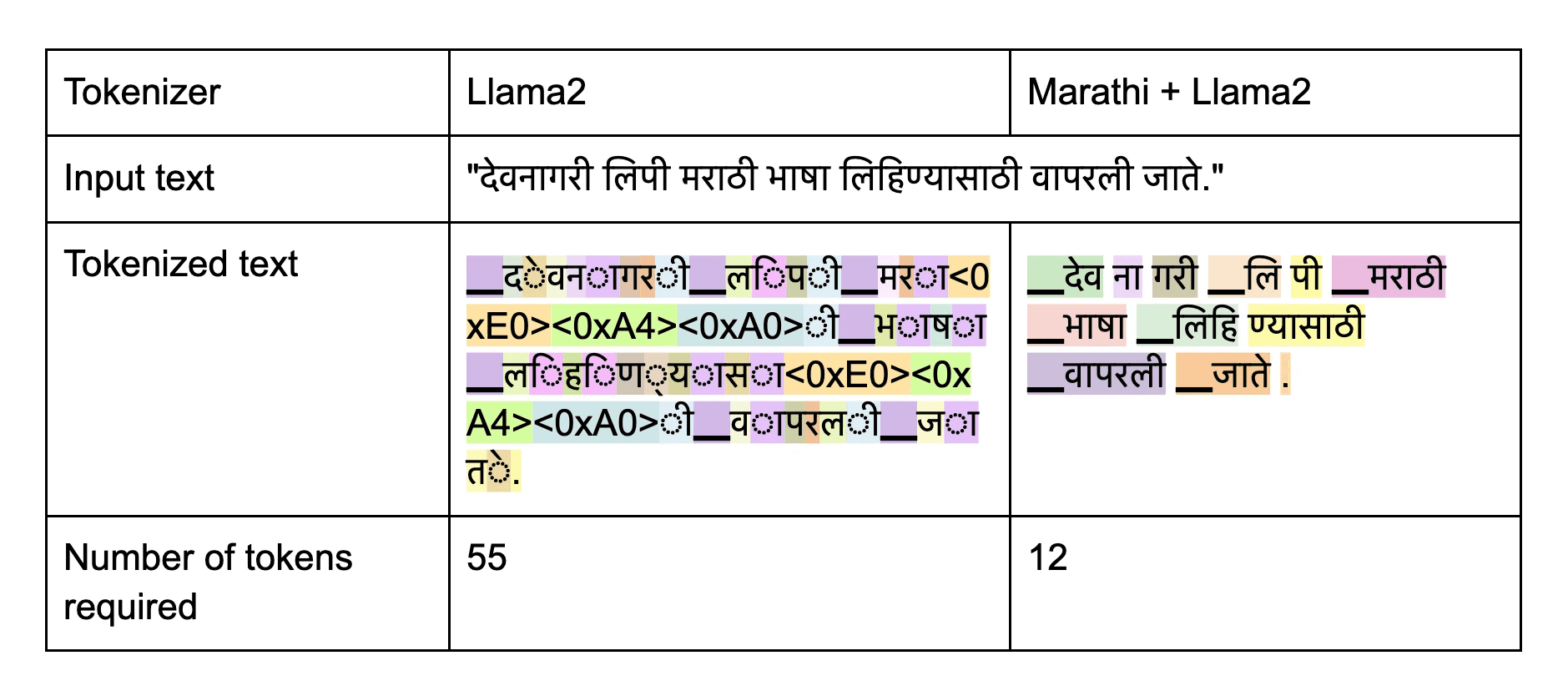
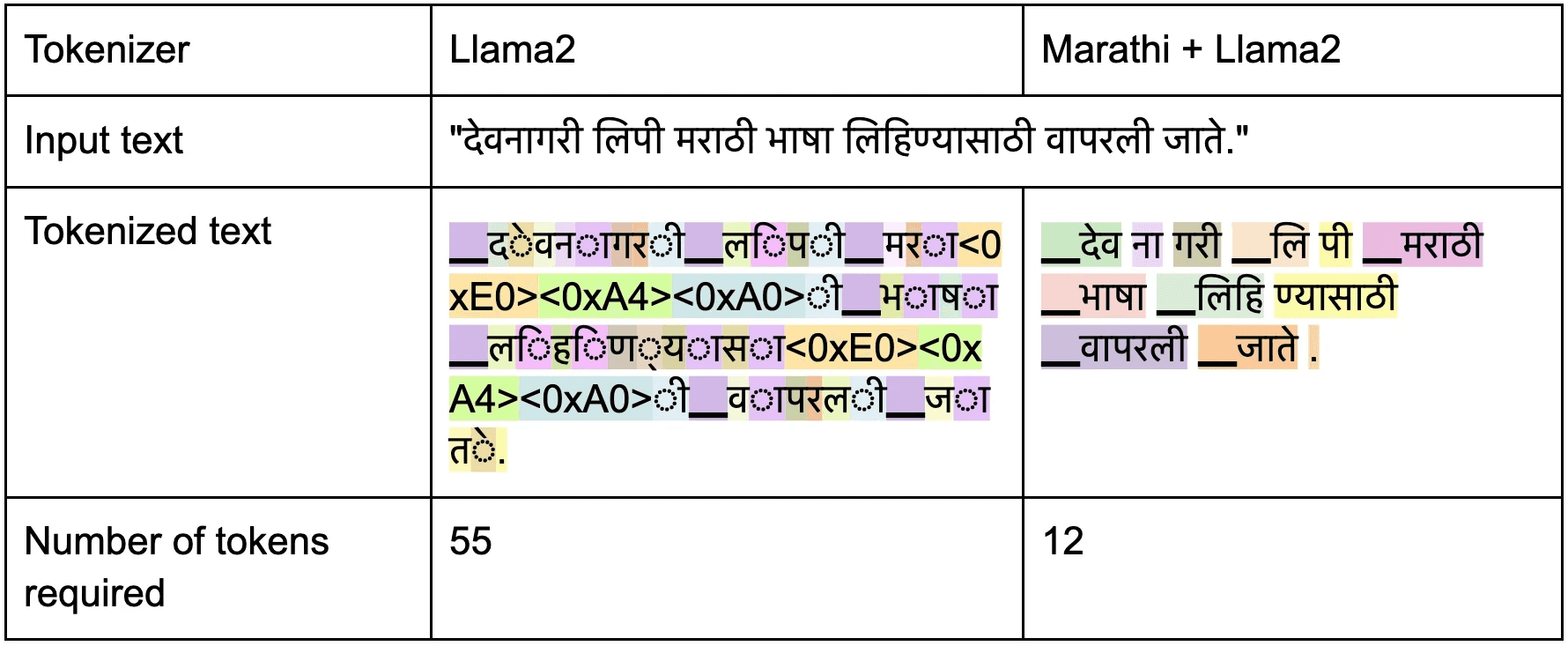
Tokenizer
Meta's Llama tokenizer faces a significant challenge while handling non-English languages due to the increased number of tokens required for representation. Even the most fundamental characters in Marathi require 3-5 token IDs. This increased number of tokens imposes an additional overhead on our model to learn the language. To address this issue, we opt to train a SentencePiece tokenizer specifically for Marathi. This results in the addition of close to 15000 new tokens to the existing 32000 tokens of Llama2.
Pretraining
During the pretraining phase of our large language model, the model was exposed to a vast corpus of text data comprising approximately 2 billion Marathi tokens. This corpus primarily consisted of newspaper data spanning the years 2016 to 2022, sourced primarily from the CulturaX dataset. In addition to this, we supplemented our training data with additional sources such as l3cube, ai4bharat, and other internet-based datasets.
# LoRA config
peft:
r: 64
lora_alpha: 128
target_modules:
[
"q_proj", "v_proj",
"k_proj", "o_proj",
"gate_proj", "up_proj",
"down_proj",
]
lora_dropout: 0.05
bias: "none"
task_type: "CAUSAL_LM"
modules_to_save: ["embed_tokens", "lm_head"]
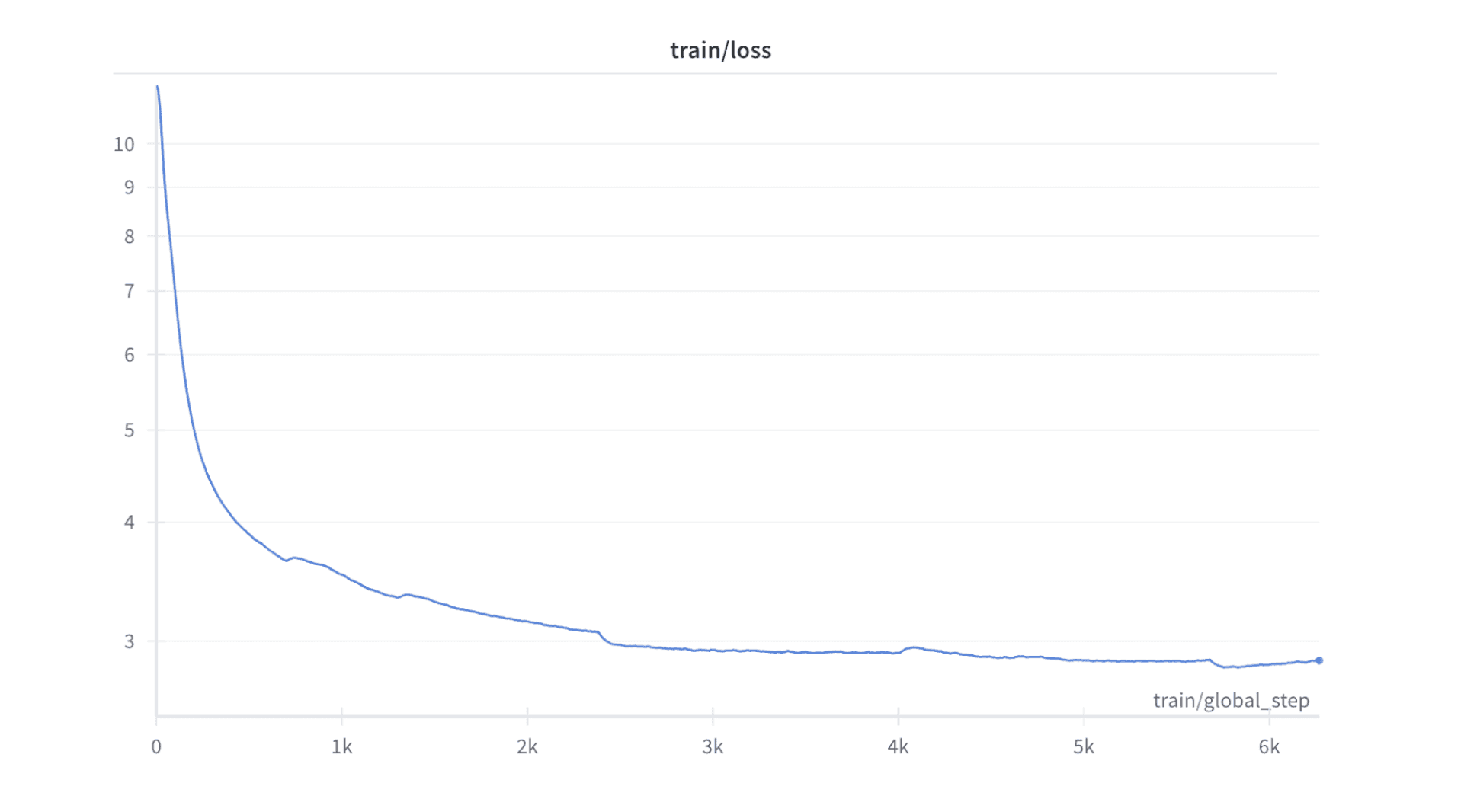
Our model was pretrained using a single A100 80GB GPU on the QBlocks platform. We chose bfloat16 as training precision due to stability issues with float16 precision.
We used Parameter efficient finetuning for pretraining, using Low Rank Adaptation (LoRA), to achieve a training loss of approximately 2.8 after training for almost 2 days.
NOTE
It is important to resize the embedding layer and corresponding language modeling head of Llama model to incorporate addition of new vocabulary in existing llama tokenizer. The method below handles the resizing mentioned above. For improving the performance of model training, it is crucial to pad embedding matrix to multiple of 64. For more information refer to the appendix below.
# after loading llama model
model.resize_token_embeddings(
len(new_tokenizer),
pad_to_multiple_of=64,
)
Finetuning
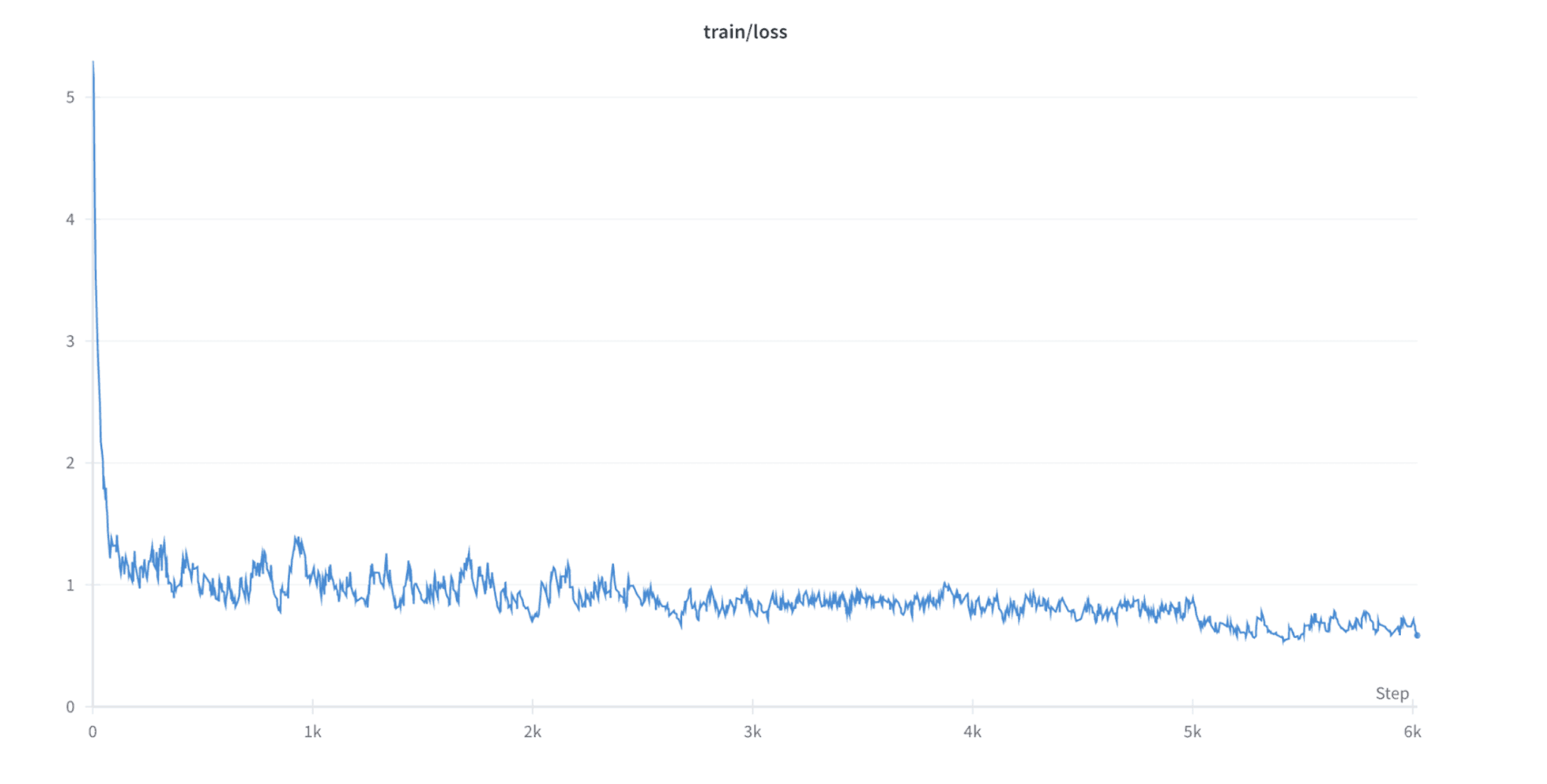
Our fine-tuning process involves utilizing approximately 200K Marathi instructions, which required translating the Alpaca dataset to Marathi using Google translate. However, due to inaccuracies in the translations, we had to meticulously clean numerous data points to ensure coherence in both instructions and responses within the dataset. In addition to the Alpaca instructions, we incorporated additional datasets such as ai4bharat/IndicQuestionGeneration, ai4bharat/IndicSentiment, and ai4bharat/IndicParaphrase, for further fine-tuning. We ran finetuning job for close to 12 hours on A100 40GB on the Google colab, with training precision bfloat16. We achieved a fine-tuning loss of approximately 0.7. We deliberately exclude code related instructions from the fine-tuning dataset.
Inference
You can run inference on Google colab, using the demo notebook here.
Attaching some examples of Misal-7B model performing reading comprehension task below.


Prompt Template
आपण एक मदतगार, आदरणीय आणि प्रामाणिक सहाय्यक आहात.
नेहमी शक्य तितकी उपयुक्त उत्तर द्या. तुमची उत्तरे हानिकारक, अनैतिक, वर्णद्वेषी, लैंगिकतावादी, हानिकारक, धोकादायक किंवा बेकायदेशीर नसावीत. कृपया खात्री करा की तुमची उत्तरे सामाजिक दृष्टिकोनाने निष्पक्ष आणि सकारात्मक स्वरूपाची आहेत. जर एखाद्या प्रश्नाला काही अर्थ नसेल किंवा वस्तुस्थितीशी सुसंगती नसेल, तर उत्तर देण्याऐवजी काहीतरी बरोबर का नाही हे स्पष्ट करा. तुम्हाला एखाद्या प्रश्नाचे उत्तर माहित नसल्यास, कृपया चुकीची माहिती देऊ नये.
### Instruction:
<instruction>
### Input:
<input data>
### Response:
Evaluation
We did a manual round of evaluations using internet data (we have released the evaluation data here). This is a fairly small dataset with 100 questions taken from the internet. We understand that a better evaluation method is needed to benchmark our model, this being the first iteration we decided to proceed with manual evaluation.
Our main aim was to see if the model understands basic instructions, if so how well is it able to understand it, hence we have limited our evaluation to Reading comprehension, Translation, Sentiment Analysis, Paraphrasing like tasks.
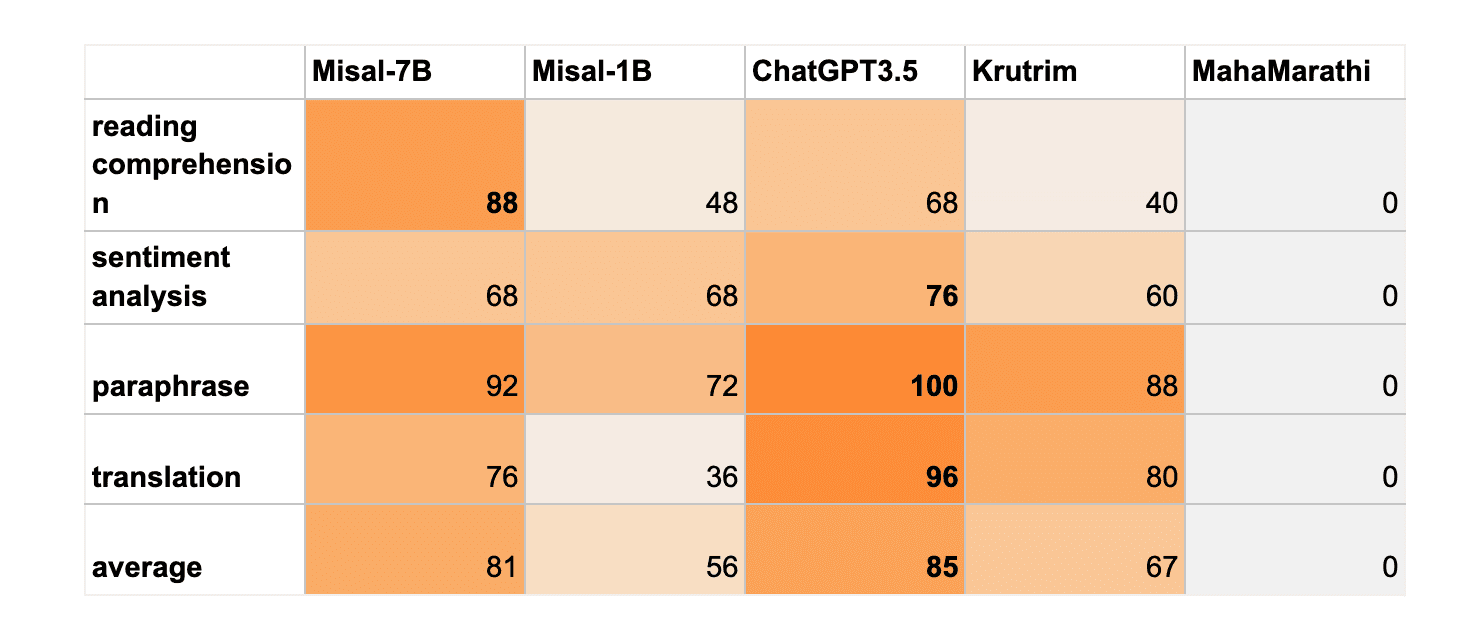
Summary
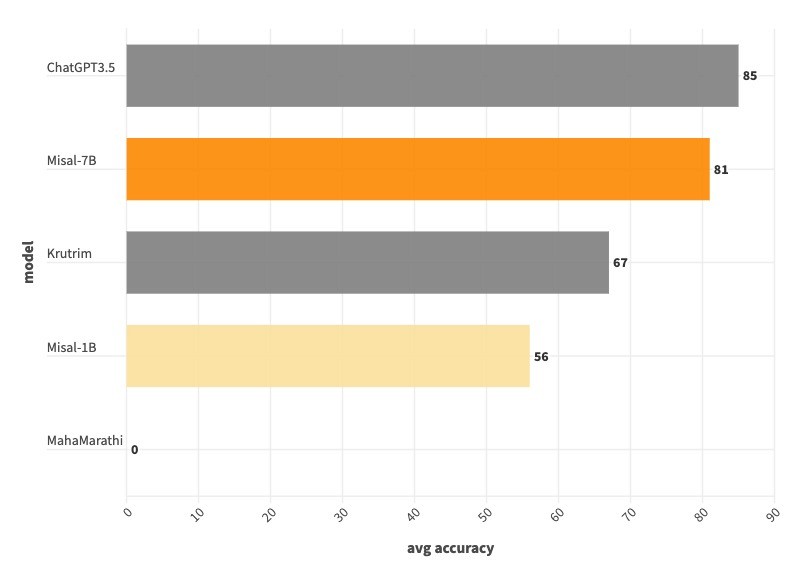
Our model, Misal-7B performs bettern than ChatGPT 3.5 at reading comprehension.
While we are not able to perform better than ChatGPT 3.5 on remaining tasks like sentiment analysis, paraphrasing, translation, Misal-7B model beats Ola Krutrim at all the tasks except translation.
We also evaluated marathi-llm/MahaMarathi-7B-v24.01-Base model which is mentioned to be instruction fine tuned as per the readme here, model outputs were random in nature suggesting that no finetuning was done.
NOTE
Misal-1B, built upon the TinyLlama model for Marathi, demonstrates an understanding of the language but currently falls short of Misal-7B in performance. This might be due to its smaller size and the data used for training TinyLlama.
However, we're actively working on improvements, we aim to significantly enhance Misal-1B's capabilities and bring it closer to its full potential.
Refining Misal-7B: Areas of Focus
While Misal-7B demonstrates strong language capabilities, there are a few areas where it can be further refined:
- Creative Content Generation: While proficient in many areas, Misal-7B may require additional fine-tuning to excel at creative tasks such as writing essays, emails, or poems.
- Conciseness and Relevance: In certain cases, the model's responses may be overly verbose. Improving its ability to provide concise and focused answers is a key area of focus.
- Number Formatting: There's room for improvement in accurately formatting numbers, especially within numbered lists.
- Repetition Reduction: In longer outputs, the model may occasionally repeat words or phrases. Refining its ability to generate diverse and varied language is an ongoing effort.
References
- Chinese Llama codebase github
- Malyalam Llama codebase github
- Tamil Llama codebase github
- Tokenizer and embedding length tweet by Andrej Karpathy